|
Theory’s pivotal importance has been continuously emphasized in the information systems (IS) discipline ever since its inception. The ability to understand and contribute to theory is an important qualification in the practice of research. Recently we see some of our reference disciplines turn towards reviving their examination of the concept and how it can help producing high quality scholarly contributions.
In light of this trend, we suggest that also the IS discipline should intensify its discussion of theory and theorizing. With a recent publication, we thus intend to synthesize and reflect upon the debate on theories and theorizing in the IS field. As such, our key contribution is to inform (new) authors about opportunities in theorizing and help them put the concept of theory to work for them. Through this, we hope to advance and support the discipline’s current strive towards more theoretical thinking and the increasing demand for theoretical contributions. The research results have recently been accepted for publication: Müller, B. and Urbach, N. (2013) The Why, What and How of Theories in Information Systems Research, Proceedings of the 34th International Conference on Information Systems (ICIS 2013), December 15-18, Milano, Italy. (Link)
0 Comments
By intelligently using the information in and around them, organizations are able to improve their decision-making and better realize their objectives. Some authors even claim that organizations may lose competitiveness by not systematically analyzing the available information. However, to obtain the desired insights, data need to be sourced, stored, and analyzed. During the past years, accessing and processing the collected, voluminous, and heterogeneous amounts of data has become increasingly time consuming and complex. With a total of 1.8 zettabyte in 2011, the amount of generated data has not yet reached its climax: as expected by IDC, a global provider of IT market intelligence, the total amount of data collected until the end of 2012 is estimated to be 1.48 times the amount of data collected in previous years, with more than 90% of this data being unstructured. Businesses increasingly use these data masses provided by millions of networked sensors in mobile phones, cashier systems, automobiles, or weather stations to learn more about their customers, suppliers, and operations. This development raises the question of how companies manage to cope with the characteristics of the ever-increasing amount of data, referred to as Big Data. In a recent research project we aimed at providing a set of organizational contingency factors that influence different Big Data strategies organizations may implement. In order to do so, we reviewed existing literature to identify different Big Data strategies as well as contingency factors and synthesized both into a contingency matrix that may support practitioners in choosing a suitable Big Data strategy for their specific context. 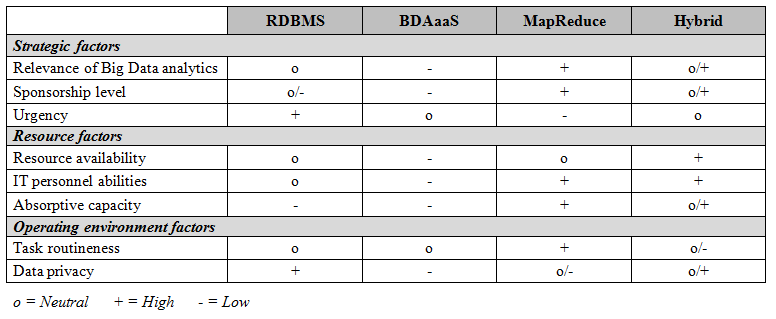 Impact of identified contingency factors on Big Data strategy choice Based on our analysis, we found that different organizational environments pursue different requirements on a Big Data strategy. To better support practitioners in Big Data strategy choice, we compared the four identified Big Data strategies regarding how well they addressed each of the contingency factors. For instance, when the relevance of Big Data analytics is high in a company, the MapReduce strategy seems most fruitful (resulting in a “+” assessment). However, also a hybrid solution might be valuable in case it follows a MapReduce-dominant approach. If in turn an RDBMS-dominant implementation is chosen, the hybrid strategy is only slightly better than a “pure” RDBMS approach (resulting in a “+/o” assessment).
The research results have recently been accepted for publication: Ebner, K., Bühnen, T. and Urbach, N. (2014) Think Big with Big Data: Identifying Suitable Big Data Strategies in Corporate Environments, Proceedings of the 47th Hawaii International Conference on Systems Sciences (HICSS-47), January 6-9, Hilton Waikoloa, Big Island. (Link) The fast development of information technology (IT) and the rise of the Internet have resulted in new ways that people deal with information and interact and communicate with each other. Today a plethora of information systems (IS) exist that aim at supporting individuals, organizations, or other entities in deriving advantages from these new possibilities. However, it is often not clear to what extent such IS achieve their purpose. This lack of clarity is not surprising; assessing the impact of IS is difficult because of problems such as the difficulty of assessing benefits using tangible numbers. IS success research, which has been underway for more than three decades, has suggested various models and constructs to measure and explain IS success. IS success, as the ultimate dependent variable, is typically measured in terms of its effect – often labeled “impact” or “net benefit” – on a particular entity. Net benefit is often regarded as the most important success measure because it captures both the positive and the negative effects of IS on users and other entities. However, because of its multi-dimensionality, IS success can be evaluated from several perspectives and at various levels, making it difficult for researchers and practitioners to agree on the best way to measure the impact of IS. It has been suggested to evaluate the impact of IS on the individual and the organizational level. However, some researchers have criticized that these two levels are only two points on a continuum of possible beneficiaries. Because of this criticism, the understanding of the net benefit construct was significantly broadened in order to leave room for further expansion to investigate other dimensions of impact or benefit. Although research has suggested the investigation of other dimensions, such as workgroups or society, the studies that have adopted such dimensions are rare. Therefore, the full variety of potential dimensions of IS impact, their differentiation, and potential approaches to their measurement remain unclear. While the literature has provided an in-depth analysis of the independent variables of IS success, to our knowledge no overview of contemporary dimensions of IS impact and their operationalizations has yet been presented. 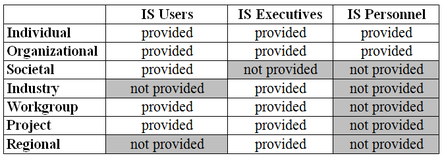 IS Impact Framework (ISIF) Scheme Accordingly, in a recent research project, our goal was to synthesize literature on IS success and to propose a framework of potential IS impact dimensions, along with measures we identified in the literature that are suitable for operationalizing them. As a result, we provide an IS Success Impact Framework (ISIF) that provides further insights on the nature of IS success and guides future studies on IS success by providing direction on how to measure the net benefits of IS. Our work contributes to IS research in that it (a) synthesizes and (b) extends the knowledge on IS success evaluation.
The research results have recently been accepted for publication: Herbst, A., Urbach, N. and vom Brocke, J. (2014) Shedding Light on the Impact Dimension of Information Systems Success: A Synthesis of the Literature, Proceedings of the 47th Hawaii International Conference on Systems Sciences (HICSS-47), January 6-9, Hilton Waikoloa, Big Island. (Link) |
Archives
December 2015
Categories
All
|
 RSS Feed
RSS Feed